Model evaluation is the process of measuring the performance of a trained machine learning model to ensure it is accurate, reliable, and ready for deployment. This step ensures the model performs well on unseen data and meets the desired standards for real-world applications. By assessing how well the model generalizes, model evaluation helps identify areas for improvement and validates the model's readiness for production use.
Model evaluation is a critical step in the machine learning workflow that bridges development and deployment. It ensures:
Incorporating rigorous model evaluation into your ML workflow guarantees that your machine learning solutions are not only high-performing but also reliable, interpretable, and ready for deployment in production environments.
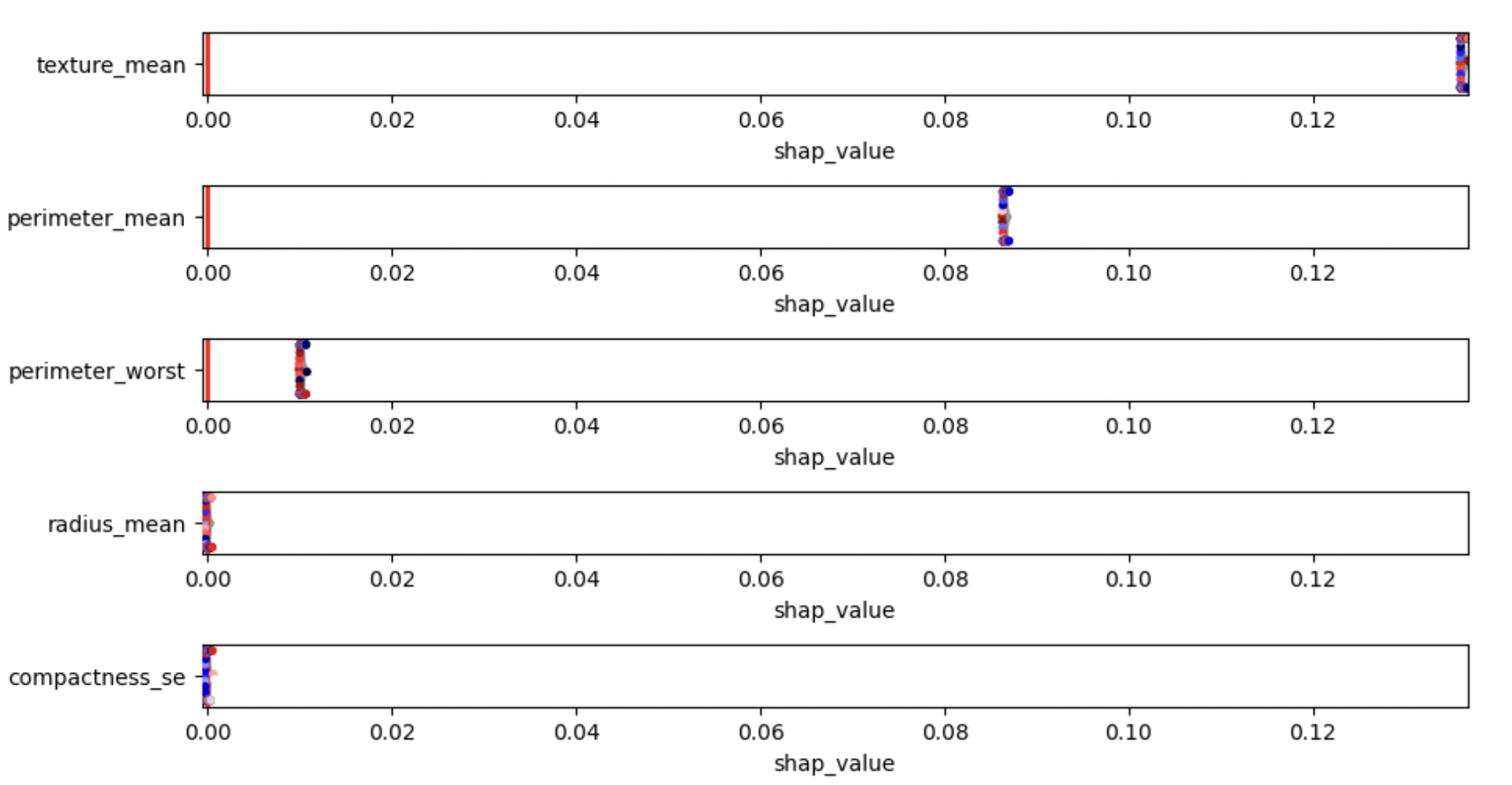 model explainability report document
model explainability report document
Save time and resources by ensuring your model works perfectly before deployment. Using AWS SageMaker tools, we rigorously validate performance metrics like accuracy, precision, and recall—minimizing costly errors in real-world scenarios.
Identify weak spots in your model with detailed error analysis. Our tools quickly highlight areas for improvement, reducing the need for trial-and-error fixes and accelerating development timelines.
Handle datasets of any size with ease. By leveraging AWS SageMaker, we evaluate models efficiently, saving you time while ensuring your solutions are production-ready.
Quickly compare multiple model versions to find the best fit for your needs. SageMaker's scalable infrastructure simplifies comparative analysis, cutting down the time spent selecting the optimal solution.
Get detailed reports on key performance metrics like F1 score, AUC-ROC, and confusion matrices. These actionable insights guide smarter decisions and better outcomes, saving you time and ensuring deployment success.
Our scalable evaluation process ensures your model stays reliable as your data grows. SageMaker's cloud tools help future-proof your investment, delivering long-term cost savings and robust performance.
© Copyright Cloudstartuptech, all rights reserved.